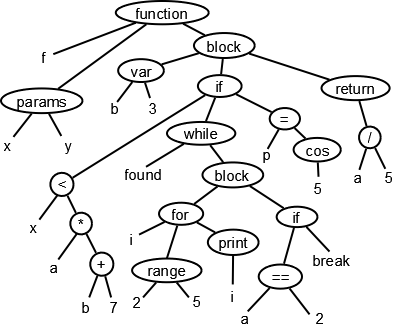
There are two primary ways that languages allow you to create a set of objects with the same (or similar) structure and behavior. In the classical approach, you define classes and then create objects from constructors associated with the class; in this case, objects are instances of the class. In the prototypal approach, you create a prototype object, and then instantiate new objects based on the prototype. Generally, a language is either classical (e.g., Java, Ruby, C#), or prototypal (e.g, JavaScript, Self, Io, Lua), though some languages let you construct objects both ways (e.g., ActionScript, Falcon).
What might prototype-based instantiations look like?
Simple Differential Inheritance
Perhaps the purest approach to a prototypal mechanism is one in which every object has an implicit link to another object, called its prototype. Whenever we look up a property in an object and it is not present, we go look in its prototype. If the property isn't present in the prototype, we search the prototype's prototype, and so on. (Writing a property is different, however; if the property doesn't exist in the object it is created right there.) Such a language might have an operator called beget which might be used like this:
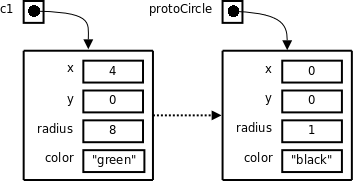
var protoCircle = {x: 0, y: 0, radius: 1, color: "black"};
var c1 = beget protoCircle;
c1.x = 4;
c1.color = "green";
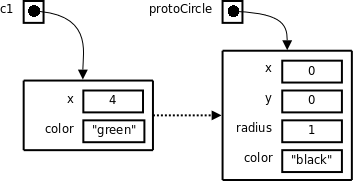
Here we have c1.x == 4, c1.y == 0, c1.radius == 1, and c1.color == "green".
We can create more circles:
var c2 = beget protoCircle;
c2.x = 4;
c2.radius = 15;
c3 = beget protoCircle;
which gives us this:
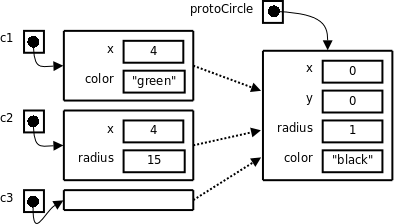
If we change any of the fields in the prototype, this change is picked up at run time by all the derived objects that haven't overridden those fields. Ditto for adding new fields to the prototype. To some people, this is convenient and flexible; to others it is ugly and error-prone. It's all those things, of course.
The prototype is also a great place to store function properties:
protoCircle.area = function () {return π * (this.radius ** 2);}
Here we've assumed we have a "this" operator which refers to the object through which the function was called (not necessarily the one along the prototype chain which ultimately contained the function).
Direct Cloning
Another approach is to define a prototype with default field values then clone it to make new objects. Cloning is different from simple differential inheritance because with cloning the new object automatically gets copy of all of the fields in the prototype, even for those that you wanted to keep the default values in the prototype. A clone operator might look like this:
var protoCircle = {x: 0, y: 0, radius: 1, color: "black"};
var c1 = clone protoCircle;
c1.x = 4;
c1.radius = 8;
c1.color = "green";Cloning means c1 is going to get all four fields:
Cloning via user-defined functions
If a language does not have a built-in clone operator, or you just don't like the look of creating an object and then doing multiple assignments to override defaults, you can do the cloning and field assignments in a function. Default fields can be nicely managed with default parameters, in languages that have them:
function newCircle(x = 0, y = 0, r = 1, c = "black") {
return {x: x, y: y, radius: r, color: c};
}
var c1 = newCircle(x => 4, r => 8, color => "green");
var c2 = newCircle(color => "yellow", r => 5);
var c3 = newCircle(_, 5, _, "blue");
or with a short circuit disjunction if you have that but no default parameters:
function newCircle(x, y, r, c) {
return {x: x || 0, y: y || 0, radius: r || 1, color: c || "black"};
}
var c1 = newCircle(x => 4, r => 8, color => "green");
With cloning, we have the problem of where to put the objects' methods. How about global variables?
function circleArea(c) {return π * c.radius ** 2;}
function circlePerimeter(c) {return 2 * π * c.radius;}
That's awful! It pollutes the global namespace. What about putting them inside the objects?
function newCircle(x = 0, y = 0, r = 1, c = "black") {
return {
x: x, y: y, radius: r, color: c,
area: function () {return π * this.radius ** 2;}
perimeter: function () {return 2 * π * this.radius;}
};
}
That's no good either — every time a circle object is created, two additional function objects are created for its area and perimeter. If we create thousands of circles we end up with thousands of identical area functions and thousands of perimeter functions sucking up memory. We should make sure we have only one copy of each (without defining global variables to access them). We want that nice little implicit link to the prototype back.
JavaScript Constructors
In JavaScript, prefixing a function call with new calls the function in a context in which the this expression refers to a newly constructed object, and, unless a return statement explicitly returns some other object, returns this newly constructed object.
function Circle(x, y, r, c) {
this.x = x || 0;
this.y = y || 0;
this.radius = r || 1;
this.color = c || "black";
}
It's also the case that JavaScript is prototypal, and weirdly so: every function is itself an object, with a property called prototype, whose value is the object that will be used as the prototype of every object created with that function. As usual, the prototype is the place where you drop in shared properties, like functions. Here's an example:
function Circle(x, y, r, c) {
this.x = x || 0;
this.y = y || 0;
this.radius = r || 1;
this.color = c || "black";
}
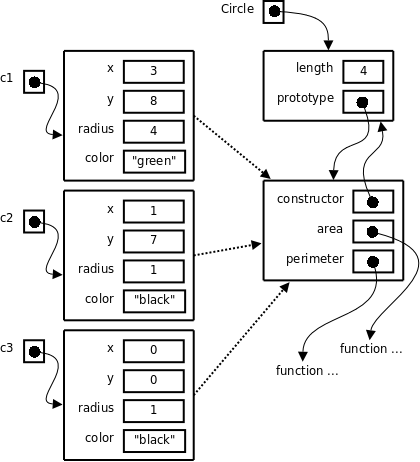
Circle.prototype.area = function () {return Math.PI * this.radius * this.radius;}
Circle.prototype.perimiter = function () {return Math.PI * 2 * this.radius;}
var c1 = new Circle(3, 8, 4, "green");
var c2 - new Circle(1, 7);
var c3 = new Circle();
Better Prototypal Patterns for JavaScript
It's pretty clear that JavaScript's new operator and the associated semantics for construction were designed to make the langusge look more classical. Douglas Crockford characterizes this beautifully by saying that "JavaScript is conflicted about its prototypal nature." He shows how to make JavaScript implement simple differential inheritance:
if (typeof Object.beget !== 'function') {
Object.beget = function(o) {
var F = function () {};
F.prototype = o;
return new F();
};
}
Our running circle example can now be written like this in JavaScript:
var protoCircle = {x: 0, y: 0, radius: 1, color: "black"};
var c1 = Object.beget(protoCircle);
c1.x = 4;
c1.color = "green";
One of the nice things about using beget is we can hide away JavaScript's crazy new operator and never have to use it again. This operator is fairly confusing and error-prone. For example, when you call functions that are supposed to be called with new but aren't, the code ends up creating or overwriting global variables. Object.beget is a nicer approach.
ECMAScript 5 Improvements to JavaScript
Current JavaScript versions (as of mid-2010) are based on the 3rd Edition of ECMAScript, known as ECMAScript 3. The newly standardized ECMAScript 5 adds many properties to the Object object, including create, which is like the beget example above. In new JavaScript:
var protoCircle = {x: 0, y: 0, radius: 1, color: "black"};
var c1 = Object.create(protoCircle, {
x: {value: 4},
color: {value: "green"}
});
Much better.